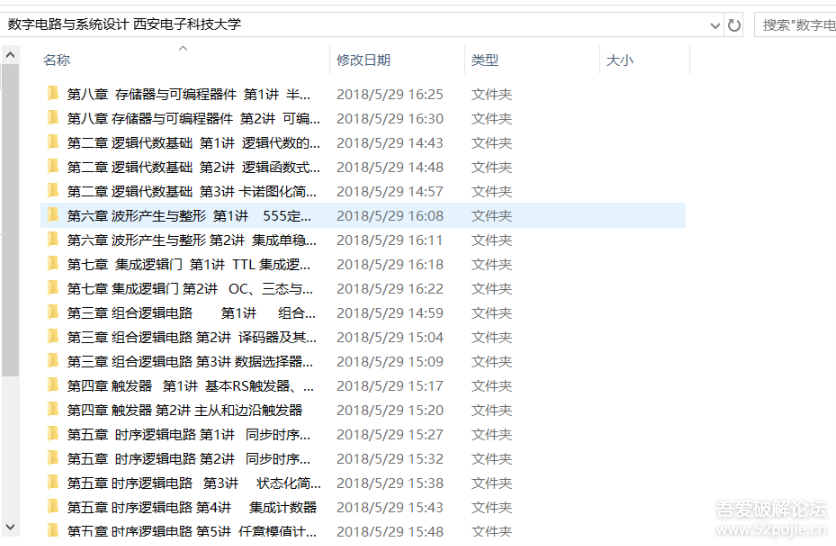
考试前准备突击一下,就看上了mooc的视频,视频是不错,但是官网并没有提供下载,学校也不是啥时候都有网,就想着把他下载下来,首先在电脑的浏览器里面抓了一下包,发现可以抓到视频,也可以下载,但一个一个手动下载太慢了,折腾了半天发现我水平有限,没法能批量获取到下载地址。

然后就考虑到了手机端app,也试着抓了一下包,很容易的就发现了一个post请求了一个很长的json字符串,粗略的看一下,视频下载地址来了,还有不同的清晰度。
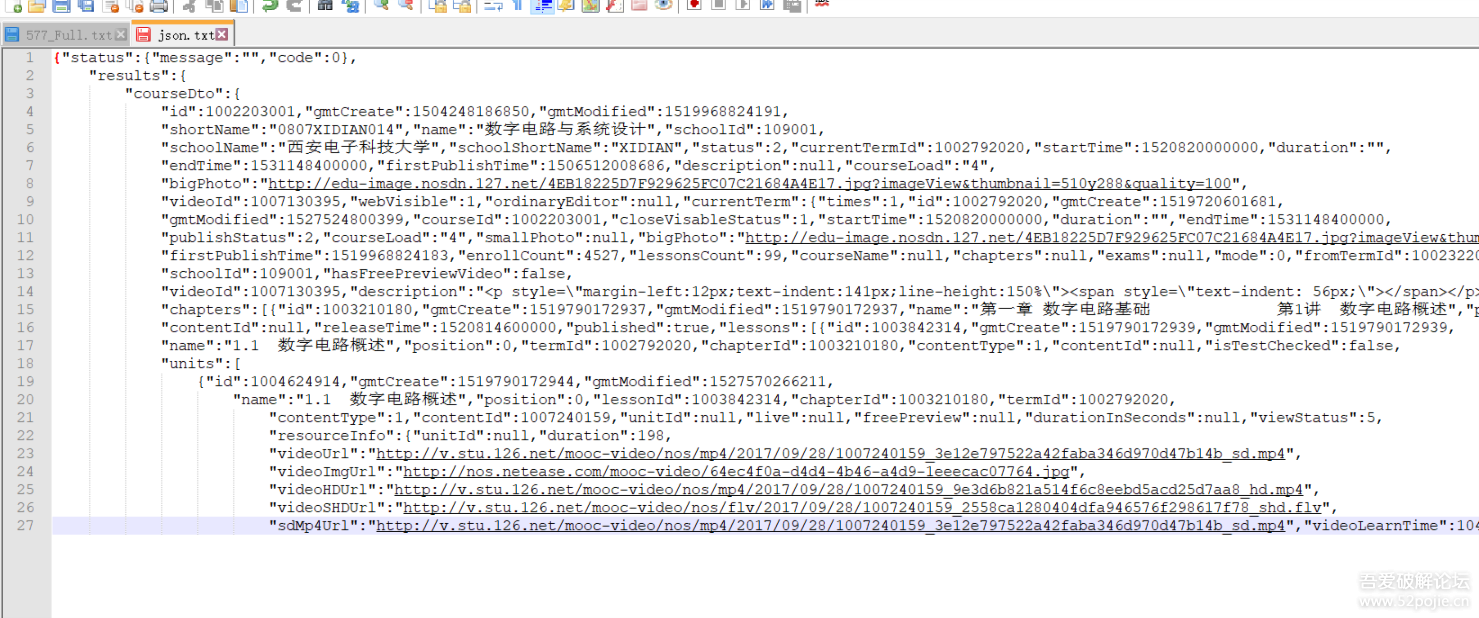
接下来的事情就简单了,用python写一个脚本,把所有的视频下载就好了
1 |
|
需要的支持库:request模块
来看看下载好的结果